Jak napisałbyś program, który szacowałby wycenę pojazdu tak, jak w powyższych przykładach?
Nie mając wiedzy o uczeniu maszynowym, zapewne będziesz próbował napisać jakieś proste reguły pomocne w oszacowaniu ceny pojazdu:
Jeśli będziesz pracować nad tym programem przez wiele godzin, to możesz stworzyć coś, co ma szansę działać. Jednak musisz wziąć pod uwagę fakt, że program nigdy nie będzie idealny i będzie miał problem z nadążeniem za wciąż zmieniającymi się cenami rynkowymi.
Czy więc nie byłoby prostsze, gdyby to komputer posiadał umiejętność wymyślenia za nas, w jaki sposób wykorzystać tę funkcję? Jeśli dostaniemy poprawny wynik, czyli jeśli ta funkcja wykona swoje zadanie, to jej dokładne działanie nas nie obchodzi. Nieprawdaż?
Jednym ze sposobów myślenia o tym zadaniu byłoby porównanie ceny pojazdu do pysznej potrawy jednogarnkowej, gdzie składnikami przysmaku byłyby wiek pojazdu, wyposażenie oraz marka i model to składniki „przysmaku”. Jeżeli jesteśmy w stanie oszacować, jak mocno każdy składnik wpływa na ostateczną cenę pojazdu, być może istnieją współczynniki proporcji poszczególnych składników, których wymieszanie zaowocuje określoną ceną końcową?
Podobne rozumowanie pozwoliłoby na redukcję funkcji do czegoś takiego:
Zwróćmy uwagę na pogrubione tajemnicze ciągi cyfry: .841231951398213, 1231.1231231, 2.3242341421 i 201.23432095. To są nasze przykładowe wagi. Jeśli odszyfrowalibyśmy idealne wagi, które działają dla każdego pojazdu, nasza funkcja mogłaby trafnie przewidywać ceny pojazdów!
Trywialny sposób, żeby znaleźć wagi, to wykonanie takiej procedury:
Krok 1:
Zacznij ze wszystkimi wagami ustawionymi na 1.0:
Krok 2:
Wykonaj funkcję dla każdego pojazdu, którego dane posiadasz, i zobacz, jak bardzo funkcja myli się w zgadywaniu właściwej ceny.
Użyj funkcji do oszacowania ceny każdego z pojazdów.
Na przykład, jeśli pierwszy został sprzedany za 250000 złotych, ale nasza funkcja odgadła 178 000 złotych, pomyłka wynosi 72 000 złotych dla tego jednego auta.
Teraz należy obliczyć kwadrat odchylenia od właściwej ceny dla każdego ze sprzedawanych aut. Powiedzmy, że w swoim zbiorze danych miałeś 500 sprzedanych samochodów i kwadrat odchylenia od ceny wzorcowej dla każdego z samochodów wynosił w sumie 82 123 373 złotych. To jest wskaźnik tego, jak „nieprawidłowo” nasza funkcja szacuje ceny samochodów.
Teraz weźmy końcową sumę wszystkich sprzedaży i podzielmy ją przez 500, aby uzyskać średnią tego, jaki błąd został popełniony dla indywidualnego pojazdu. Nazwijmy to średnim błędem cenowym naszej funkcji.
Jeśli będziemy potrafili zmniejszyć ten średni błąd cenowy do 0, modyfikując wagi, twoja funkcja będzie idealna. To by znaczyło, że w każdym przypadku nasza funkcja idealnie szacuje cenę pojazdu w oparciu o posiadane dane wejściowe. W takim przypadku cel został osiągnięty – średni błąd został obniżony tak bardzo, jak to tylko było możliwe, w odniesieniu do różnych wag.
Krok 3:
Powtarzamy krok 2 wielokrotnie, wybierając każdą możliwą kombinację wag. Jeżeli jakakolwiek kombinacja wag poprawia wynik (przybliża średni błąd do wartości 0) to staje się ona kolejną wyjściową kombinacją wag. Kiedy znajdziemy kombinację wag, które działają, problem jest rozwiązany!
A teraz czas na prawdziwe wyzwanie…
To proste, prawda? Pomyślmy, czego do tej pory dokonaliśmy. Wzięliśmy pewne dane, zostały one wpisane w trzy proste etapy, w efekcie czego otrzymaliśmy funkcję, która oszacuje cenę pojazdu o określonych parametrach.
Oto kilka faktów, które na prawdę Cię zadziwią: Badania w wielu dziedzinach (np. lingwistyka/tłumaczenia) na przestrzeni ostatnich 40 lat pokazały, że podstawowe algorytmy uczenia maszynowego potrafią wymieszać „potrawę”, wykonując swoje zadania nierzadko lepiej od ludzi tam, gdzie ludzie próbują znaleźć bezpośrednie i jawne zasady samodzielnie. Taki „bezmyślny” sposób uczenia maszynowego potrafi pokonać w tym zadaniu zwykłych ludzi, ale też ekspertów.
Końcowa funkcja jest naprawdę bezmyślna. Nie jest ona nawet w stanie wiedzieć, czym jest wyposażenie albo wiek pojazdu. Ona wie jedynie tyle, że wszystkie dane trzeba tak wymieszać, aby uzyskać poprawny wynik.
Prawdopodobne jest, że nie będziemy mieli najmniejszego pojęcia, dlaczego dana kombinacja wag w określonej funkcji działa poprawnie. Tak właśnie została napisana funkcja, której tak naprawdę nie rozumiemy. Możemy jednak pokazać, że działa ona całkiem poprawnie.
Wyobraźmy sobie, że zamiast selekcjonować parametry takie jak „wiek_pojazdu”, albo „marka”, nasza funkcja będzie sobie po prostu pobierała zbiór liczb. Powiedzmy, że każda liczba reprezentuje jasność pojedynczego piksela w zdjęciu zrobionym aparatem umieszczonym na dachu Twojego samochodu. Teraz powiedzmy, że zamiast wytworzyć odpowiedź na pytanie o „cenę”, funkcja będzie szacować wielkość nazwaną “liczba_stopni_do_skrętu_kierownicą”. Właśnie stworzyliśmy funkcję, która samodzielnie potrafi sterować naszym samochodem!
Trochę to dziwne, nieprawdaż? O co chodzi z tą „każdą możliwą kombinacją wag” w kroku 3? Tak naprawdę nie jesteśmy w stanie spróbować każdej kombinacji i wszystkich możliwych wag, aby znaleźć tą, która będzie pracować najlepiej. To by trwało wiecznie, bo liczby mogą być testowane w nieskończoność.
By tego uniknąć, matematycy wynaleźli wiele sprytnych sposobów szybkiego znajdywania dobrych wartości tych wag bez potrzeby testowania zbyt wielu. Oto jeden z tych sposobów:
Najpierw, napisz proste równanie, które reprezentuje krok 2.:
$$Koszt = {\sum_{i=1}^{500}( Przewidywania(i) – PrawdziwaOdpowiedź(i))^2\over 500 \cdot 2}$$
To jest nasza funkcja kosztu.
Teraz przepiszmy dokładnie to samo równanie, ale używając żargonu matematycznego uczenia maszynowego (na razie możesz to zignorować):
$$J(\Theta) = { 1 \over 2m } \sum_{i=1}^{m}(h_0(x^{(i)}) – y^{(i)})^2$$
Θ reprezentuje nasze bieżące wagi. J(Θ) oznacza ‘koszt dla naszych aktualnych wag’.
To równanie odzwierciedla, jak złe jest nasze szacowanie dla aktualnego zbioru wag.
Jeśli narysujemy tę funkcję kosztu dla wszystkich możliwych wartości wag dla parametrów „wiek_pojazdu” i „wyposażenie”, dostaniemy wykres wyglądający mniej więcej tak:
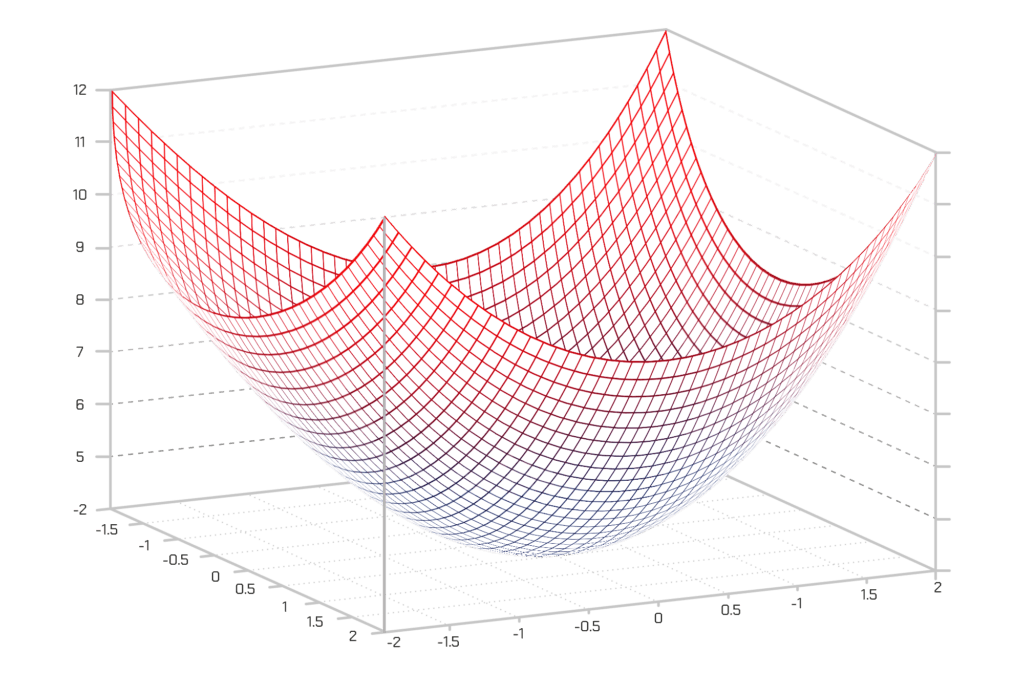
W tym wykresie najniższy punkt, zaznaczony na niebiesko, jest tym, dla którego nasz koszt jest najmniejszy – dlatego też nasza funkcja myli się tu najmniej. Najwyższy punkt jest tam, gdzie mylimy się najbardziej. W takim razie, jeśli możemy znaleźć wagi, które przenoszą nas w punkt najniższy, mamy naszą odpowiedź!
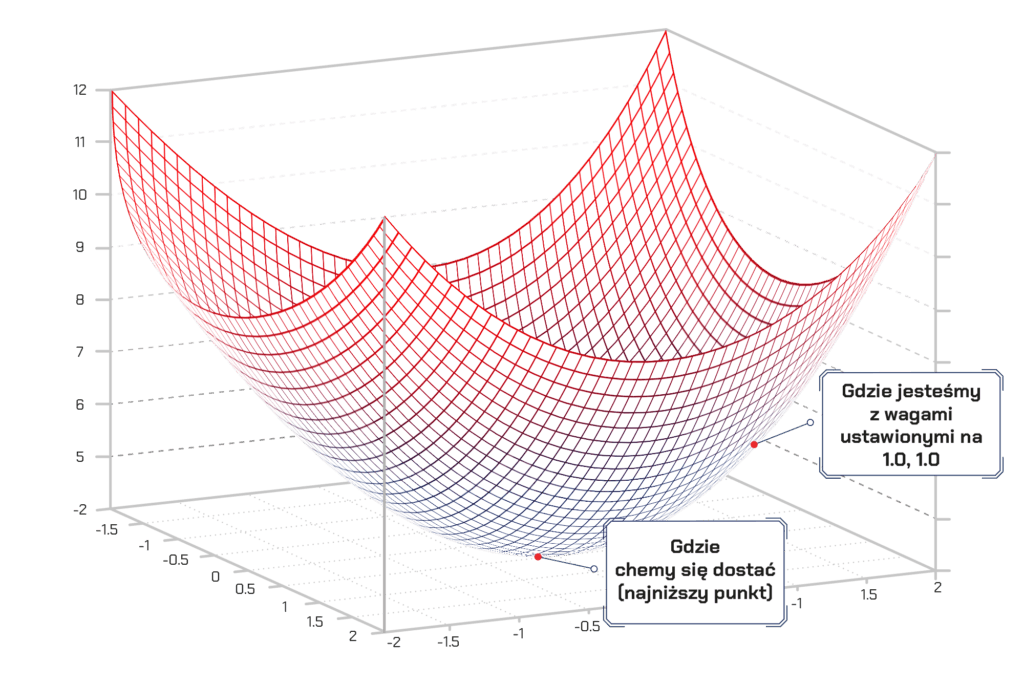
W takim wypadku koniecznie musimy jedynie zmodyfikować nasze wagi tak, abyśmy „szli w kierunku doliny”, czyli w kierunku niższych wartości na tym wykresie. Jeśli będziemy robić małe zmiany wag, które zawsze przenoszą nas niżej, dojdziemy tam bez potrzeby wykonywania zbyt wielu kroków. Jeżeli uczyliśmy się rachunku różniczkowego, wiemy, że pochodna z funkcji mówi o tym, jak jest ona nachylona w danym punkcie.
Parafrazując, mówi nam ona, w którym kierunku mamy iść, aby obniżyć wartość funkcji dla danego punktu z naszego wykresu. I tej wiedzy możemy użyć, by podążać w kierunku naszej doliny.
Dlatego jeśli policzymy pochodną cząstkową naszej funkcji kosztu względem każdej z naszych wag, możemy odjąć tę wartość od każdej wagi. W ten sposób zbliżymy się o krok w kierunku doliny, czyli ku minimum naszej funkcji. Robiąc to kilka razy – w końcu osiągniemy dno. A tam będziemy mieli kombinację najlepszych wag dla naszego problemu.
To podsumowanie jednego ze sposobów znalezienia najlepszej kombinacji wag dla naszej funkcji – metoda nazywana metodą gradientów prostych. Nie obawiajmy drążyć tematu, jeśli jesteśmy zainteresowani szczegółami.
Chociaż do uczenia maszynowego używamy bibliotek i właściwie problem jest rozwiązywany za nas, warto wiedzieć, co dzieje się „za kulisami”.
Co więc jeszcze jest ukrywane przez metody uczenia maszynowego, a co zostało ominięte?
Algorytm trójstopniowy, który został opisany powyżej, nazywany jest analizą wieloczynnikową regresji liniowej. Szacowane jest równanie liniowe, które zostaje dopasowywane tak, by prosta przechodziła przez wszystkie punkty z danymi. Potem to równanie jest używane do odgadnięcia ceny samochodów, których nigdy nie widzieliśmy na oczy, w oparciu o informacje, w którym miejscu pojawi się on na prostej. Takie równanie jest potężnym narzędziem, dzięki któremu mamy możliwość rozwiązania prawdziwych problemów.
Niestety przedstawione tu podejście może mieć swoje zastosowanie w prostych zagadnieniach, ale niekoniecznie będzie dobrze działało w dziedzinach bardziej złożonych. To dlatego, że ceny są zależnościami dość skomplikowanymi i nie zawsze ułożą się na ciągłej linii.
Jest jednak wiele sposobów na poradzenie sobie z bardziej zawiłymi problemami. Istnieje bardzo dużo innych algorytmów uczenia maszynowego, które dają radę z danymi nieliniowymi (sieci neuronowe czy metoda wektorów nośnych z tak zwanymi kernelami). Są też sposoby na użycie regresji liniowej w taki sposób, aby przybliżyć bardziej skomplikowane funkcje do naszych danych. W każdym jednak przypadku nadal celem jest ustalenie najlepszego zestawu wag.
W niniejszym artykule problem przeuczenia sieci został zignorowany. To dosyć proste: ukończyć algorytm z wagami, które zawsze pracują w sposób poprawny dla samochodów z naszego zbioru danych uczących, ale nie pracują poprawnie dla nowych samochodów, które nie były w oryginalnym zbiorze uczącym. Są sposoby, aby zapobiec takiemu zjawisku (regulacja, użycie testów walidacyjnych). W sprawnym posługiwaniu się narzędziami uczenia maszynowego umiejętność radzenia sobie z tym problemem jest kluczowa.
Konkludując, podstawowa idea jest bardzo prosta, jednak zabiera trochę czasu i doświadczenia, by zastosować uczenie maszynowe i uzyskać zadowalające rezultaty.